Metric使用
目录 (Table of Contents)
- 简介
- MAVEN设置
- The Registry
- 五种度量类型
- Gauges
- Counters
- Histograms
- Meters
- Timers
- Reporter
- 健康检查
简介
Metrics是一个给JAVA提供度量工具的包,在JAVA代码中嵌入Metrics代码,可以方便的对业务代码的各个指标进行监控。
Metric 的使用可参考官网。
MAVEN设置
1 | <dependency> |
The Registry
Metrics的核心是MetricRegistry类,它是所有应用程序指标的容器。
1 | final MetricRegistry metrics = new MetricRegistry(); |
五种度量类型
Gauges
最基本的度量指标,返回一个值。
1 | public class QueueManager { |
测量此量表时,将返回队列中的任务数量。
在注册表中的每个指标都有一个唯一的名称,例如 “things.count”或”com.example.Thing.latency”。MetricRegistry有一个用于构造这些名字的静态辅助方法:
1 | MetricRegistry.name(QueueManager.class, "jobs", "size") |
它将返回一个类似”com.example.QueueManager.jobs.size”的字符串。
Counters
Counters只是一个AtomicLong实例的衡量标准。您可以增加或减少其值。例如,我们可能需要一个更有效的方式来衡量队列中待处理的任务:1
2
3
4
5
6
7
8
9
10
11private final Counter pendingJobs = metrics.counter(name(QueueManager.class, "pending-jobs"));
public void addJob(Job job) {
pendingJobs.inc();
queue.offer(job);
}
public Job takeJob() {
pendingJobs.dec();
return queue.take();
}
每次测量这个计数器时,它都会返回队列中的任务数量。
正如你所看到的,Counters的API略有不同:用 counter(String)而不是 register(String, Metric) 。
Histograms
Histograms(直方图 )统计 数据流中值的分布。除了最小值,最大值,平均值等之外,它还测量中值,第75,90,95,98,99和99.9百分位数。
1 | private final Histogram responseSizes = metrics.histogram(name(RequestHandler.class, "response-sizes")); |
这个直方图将以字节为单位来测量响应的大小。
Meters
Meters测量一段时间内的事件发生率(例如“每秒请求数”)。除了平均速度之外,Meters还跟踪1,5和15分钟的均值。1
2
3
4
5
6
7private final MetricRegistry metrics = new MetricRegistry();
private final Meter requests = metrics.meter("requests");
public void handleRequest(Request request, Response response) {
requests.mark();
// etc
}
将测量每秒请求的请求率。
Timer
Timer测量一段代码被调用的速率和它的持续时间的分布。
1 | private final Timer responses = metrics.timer(name(RequestHandler.class, "responses")); |
该Timer 将测量处理每个请求所需的时间(以纳秒为单位),并提供每秒请求的请求速率。
Timer 其实是 Histogram 和 Meter 的结合
Reporter
报表,用于展示统计结果
通过JMX报告Metric
1
2final JmxReporter reporter = JmxReporter.forRegistry(registry).build();
reporter.start();STDOUT, using ConsoleReporter from metrics-core
1
2
3
4
5final ConsoleReporter reporter = ConsoleReporter.forRegistry(registry)
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build();
reporter.start(1, TimeUnit.MINUTES);CSV files, using CsvReporter from metrics-core
1
2
3
4
5
6final CsvReporter reporter = CsvReporter.forRegistry(registry)
.formatFor(Locale.US)
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build(new File("~/projects/data/"));
reporter.start(1, TimeUnit.SECONDS);SLF4J loggers, using Slf4jReporter from metrics-core
1
2
3
4
5
6final Slf4jReporter reporter = Slf4jReporter.forRegistry(registry)
.outputTo(LoggerFactory.getLogger("com.example.metrics"))
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build();
reporter.start(1, TimeUnit.MINUTES);Ganglia, using GangliaReporter from metrics-ganglia
1
2
3
4
5
6final GMetric ganglia = new GMetric("ganglia.example.com", 8649, UDPAddressingMode.MULTICAST, 1);
final GangliaReporter reporter = GangliaReporter.forRegistry(registry)
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build(ganglia);
reporter.start(1, TimeUnit.MINUTES);Graphite, using GraphiteReporter from metrics-graphite
1
2
3
4
5
6
7
8final Graphite graphite = new Graphite(new InetSocketAddress("graphite.example.com", 2003));
final GraphiteReporter reporter = GraphiteReporter.forRegistry(registry)
.prefixedWith("web1.example.com")
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.filter(MetricFilter.ALL)
.build(graphite);
reporter.start(1, TimeUnit.MINUTES);
健康检查
度量标准还能够对服务的健康状况进行检查,需要引用metrics-healthchecks模块 。
首先,创建一个新的HealthCheckRegistry实例:
1 | final HealthCheckRegistry healthChecks = new HealthCheckRegistry(); |
其次,实现一个HealthCheck子类:
1 | public class DatabaseHealthCheck extends HealthCheck { |
然后用Metrics注册它的一个实例:
1 | healthChecks.register("postgres", new DatabaseHealthCheck(database)); |
运行所有注册的健康检查:
1 | final Map<String, HealthCheck.Result> results = healthChecks.runHealthChecks(); |
度量标准带有预先构建的运行状况检查:ThreadDeadlockHealthCheck使用Java的内置线程死锁检测来确定是否有线程死锁。
产品性能自测
*本文是从公司内网KB转过来的,格式有点混乱懒得改了QAZ~~
目录 (Table of Contents)
- FAQ
- 一、测试目的
- 二、测试环境
- 三、测试方法
- 四、测试结果
- 写:
- 读:
- 五、结论
- 1、指标库写性能:
- 2、指标库读性能:
FAQ
1.写入能力:多少个15秒监控周期的主机,或180秒监控周期的网络设备的数据写入
假设现场1个资源每15 S上报100个指标,则每分钟上报400个,
若部署单节点Cassandra,在redis集群状况良好的情况下,每分钟可写入80W个指标,可支持800000/400=2000个资源左右;
若部署Cassandra 集群,每分钟可写入110W个指标,可支持1100000/400=2750个资源左右;
考虑到稳定性可酌情减少资源量或增加配置。
2.读出能力:每秒完成指定数据点数查询的TPS性能峰值,以便预测可以支持什么数量的仪表盘
在三台4C*16G的Cassandra节点的配置下,稳定查询的前提下,每分钟至少400条并发请求(每条请求至少6000条元数据,大约为15分钟的数据)。
一、测试目的
测试在指定硬件条件下,指标库写入能力与读取能力。
二、测试环境
| ip | cpu | 内存 | 磁盘 | 用途 | 备注 |
|---|---|---|---|---|---|
| 个人电脑 | 4核 | 16G | 部署jmeter | ||
| 10.1.53.37 | 6核 | 8G | 部署jmeter-server | 通过jmeter来发送测试请求, 这些机器同时部署着其他产品。 | |
| 10.1.53.38 | 4核 | 16G | |||
| 10.1.53.65 | 4核 | 8G | |||
| 10.1.61.10 | 4核 | 24G | |||
| 10.1.53.39 | 4核 | 16G | 指标库、ES、租户等组件 | 该机器主要用来部署指标库 | |
| 10.1.61.117 | 4核 | 16G | 38G | kairosdb、omp等 | kairosdb 堆内存为默认的3g |
| 10.1.61.118 | 4核 | 16G | 38G | Cassandra | kairosdb 堆内存为为默认的4g, 计算公式 max(min(1/2 ram, 1024MB),min(1/4 ram, 8GB)) |
三、测试方法
测试工具为Jmeter,通过调用指标库相应的openApi测试,用jconsole 监控进程占用资源变化。
四、测试结果
写:
Ramp-up Period 决定多长时间启动所有线程。如果使用10个线程,ramp-up period是100秒,那么JMeter用100秒使所有10个线程启动并运行。每个线程会在上一个线程启动后10秒(100/10)启动。
monitor 指标上报的频率是15S一次,故此处从 以15S/s 的频率启动一个上报线程开始测试。
如组1,测试逻辑为:
每15秒启动一个线程,单个线程每次上报25个指标,重复上报500次,每分钟指标写入请求次数为5W条。
jmeter-server为1,表示只在本机运行测试;若为4,表示在4个机器上同时对指标库发起请求测试。
1.kairosdb 自带写入统计指标:
kairosdb.metric_counters - Counts the number of data points received since the last
report. Tags are used to separate one metric from another.(统计自上次上报后接收的数据量。标签用于区分指标。)
kairosdb 统计结果:
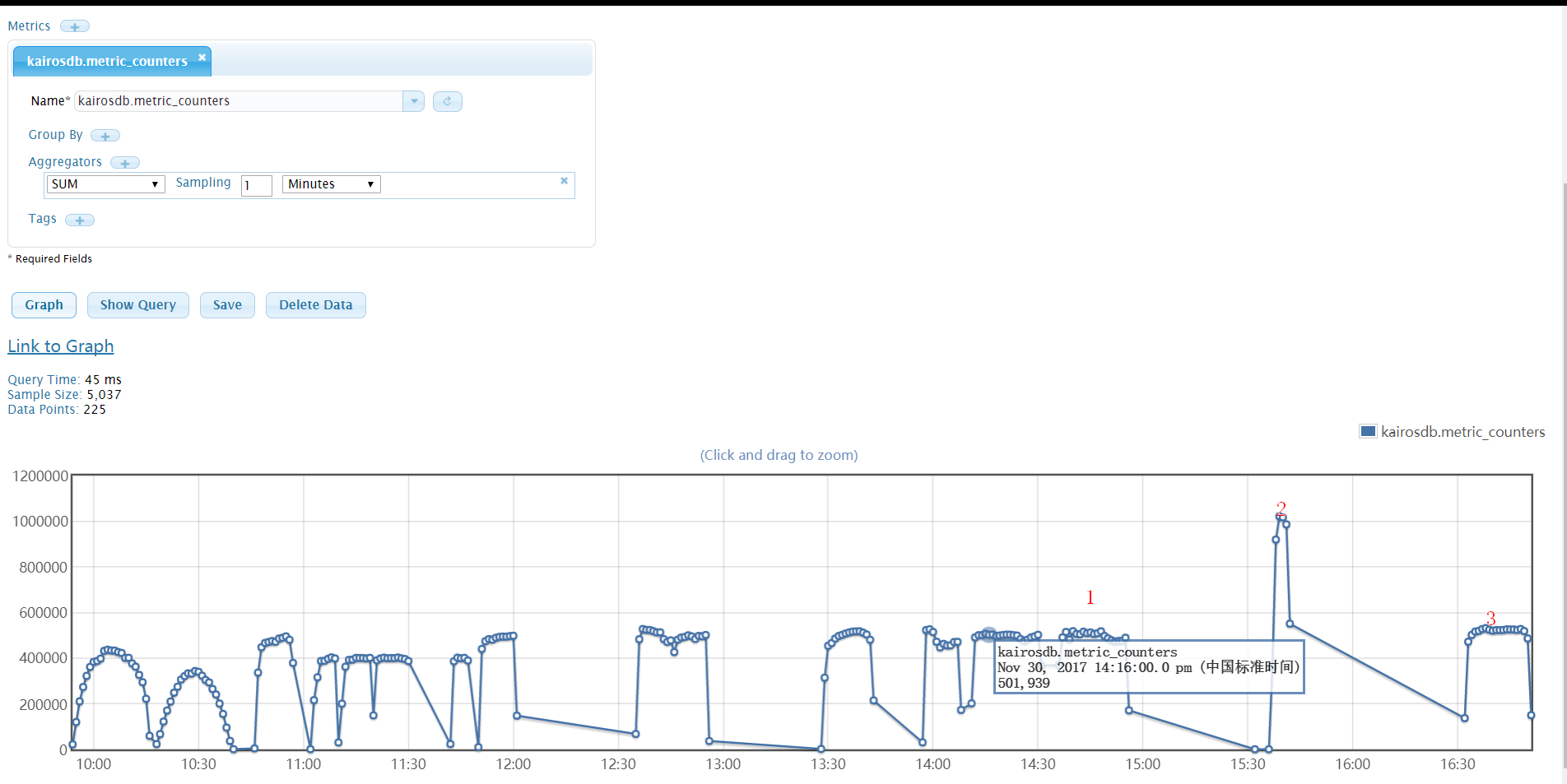
“1”处为组别12的测试结果,“2”处为直接调用kairosdb restApi 写入接口,“3”处为组别14 的结果。结果与指标库的统计日志一致。
2.时间有限,每组测试时间间隔较短,因此可能会对CPU、内存以及Cassandra状态产生影响,使结果不够准确。
注:
【1】:指标库redis 报内存不够,异常: Can’t save in background: fork: Cannot allocate memory
【2】:短时间插入大量指标会导致未压实的sstable数据太多,压实进程报可用磁盘空间不足,重新压实…恶性循环。
1 | <![CDATA[[root@localhost data_points-1e09be40c3c811e7977aa147ea7baf03]# /opt/cassandra/bin/nodetool compactionstats -H |
Cassandra报异常:
1 | <![CDATA[WARN [CompactionExecutor:46] 2017-11-28 22:26:29,785 CompactionTask.java:91 - insufficient space to compact all requested files BigTableReader(path='/opt/dbdata/cassandra/data/kairosdb/data_points-1e09be40c3c811e7977aa147ea7baf03/ma-216-big-Data.db'), BigTableReader(path='/opt/dbdata/cassandra/data/kairosdb/data_points-1e09be40c3c811e7977aa147ea7baf03/ma-237-big-Data.db') |
解决方法:
1、增大磁盘空间、
2、直接删除同一编号的sstable 大文件
3、重装Cassandra
多节点写:
1.通过观察发现,写的瓶颈在指标库的gateway,然后增加多节点的测试如下:
- 开启一个gateway、一个writer模块后,指标写入能力在 50W/分钟;
- 开启三个gateway、一个writer模块后,指标写入能力在 80W/分钟;
- 开启三个三个gateway、三个writer 模块后,指标写入能力在 85W/分钟。
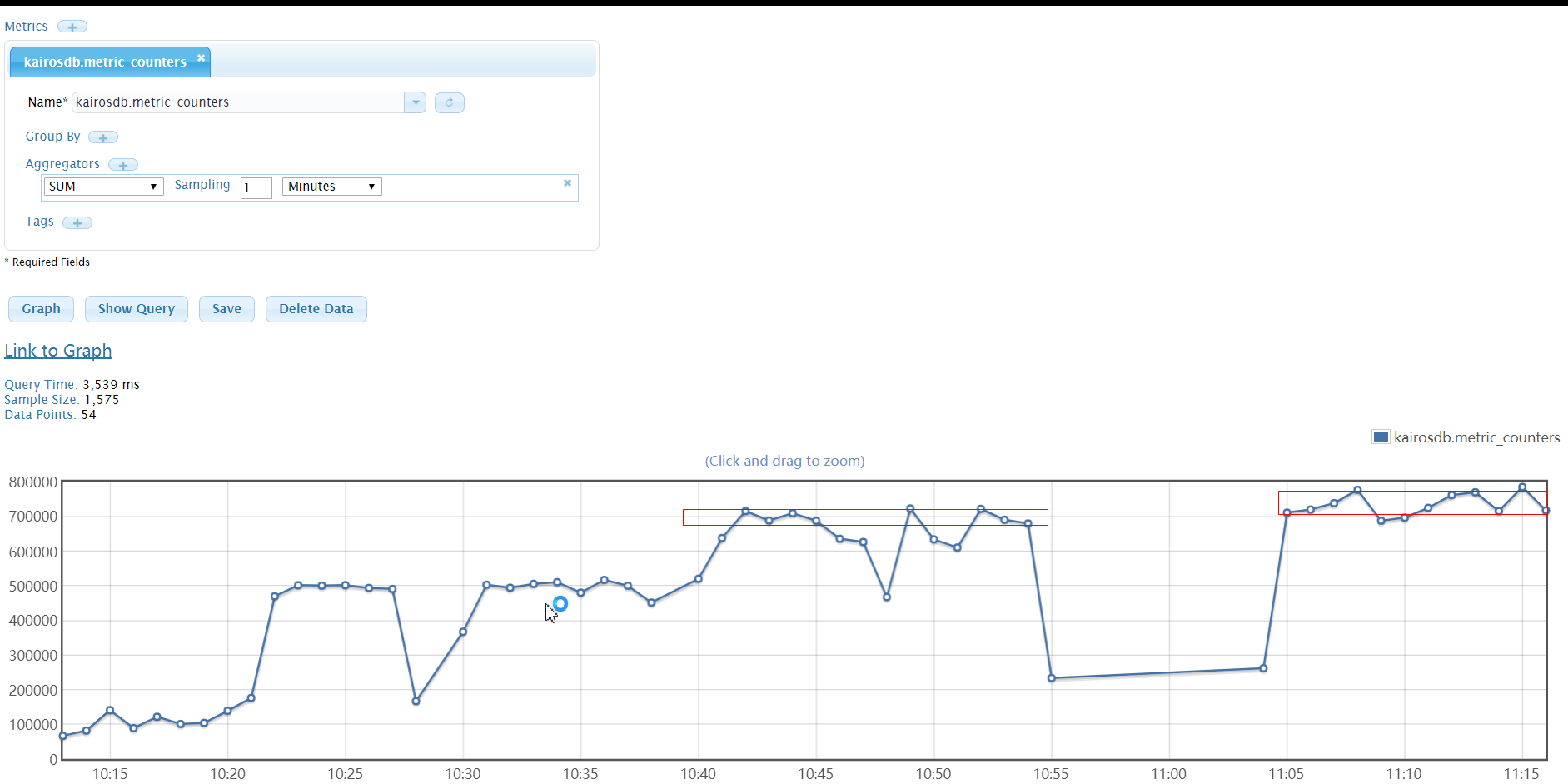
2.当部署Cassandra集群(3个节点)后,指标写入能力可以再次提升,开启三个gateway、一个writer模块,指标写入能力在 100W/分钟 ,此状态下可持续写入四个小时,期间redis会报内存不够的异常。
另外,当指标库写入在满载的情况下,指标的读取能力会受到很大影响,且写入也会偶尔报连接超时现象。
读:
指标的查询,其实是kairosdb去查Cassandra中数据。因此kairosdb查Cassandra的速度才是关键因素。而查Cassandra数据的速度,跟查询的Cassandra的row数量、元数据量等因素相关。
要模拟读取测试,就需要先调查现场实际查询的row和元数据大小。
统计局的统计如下:
上图为密集查询30分钟内指标时,从Cassandra中查询的row的行数;
中图为密集查询30分钟内指标时,从Cassandra中查询的元数据的数量;
下图为定时查询时row的行数。
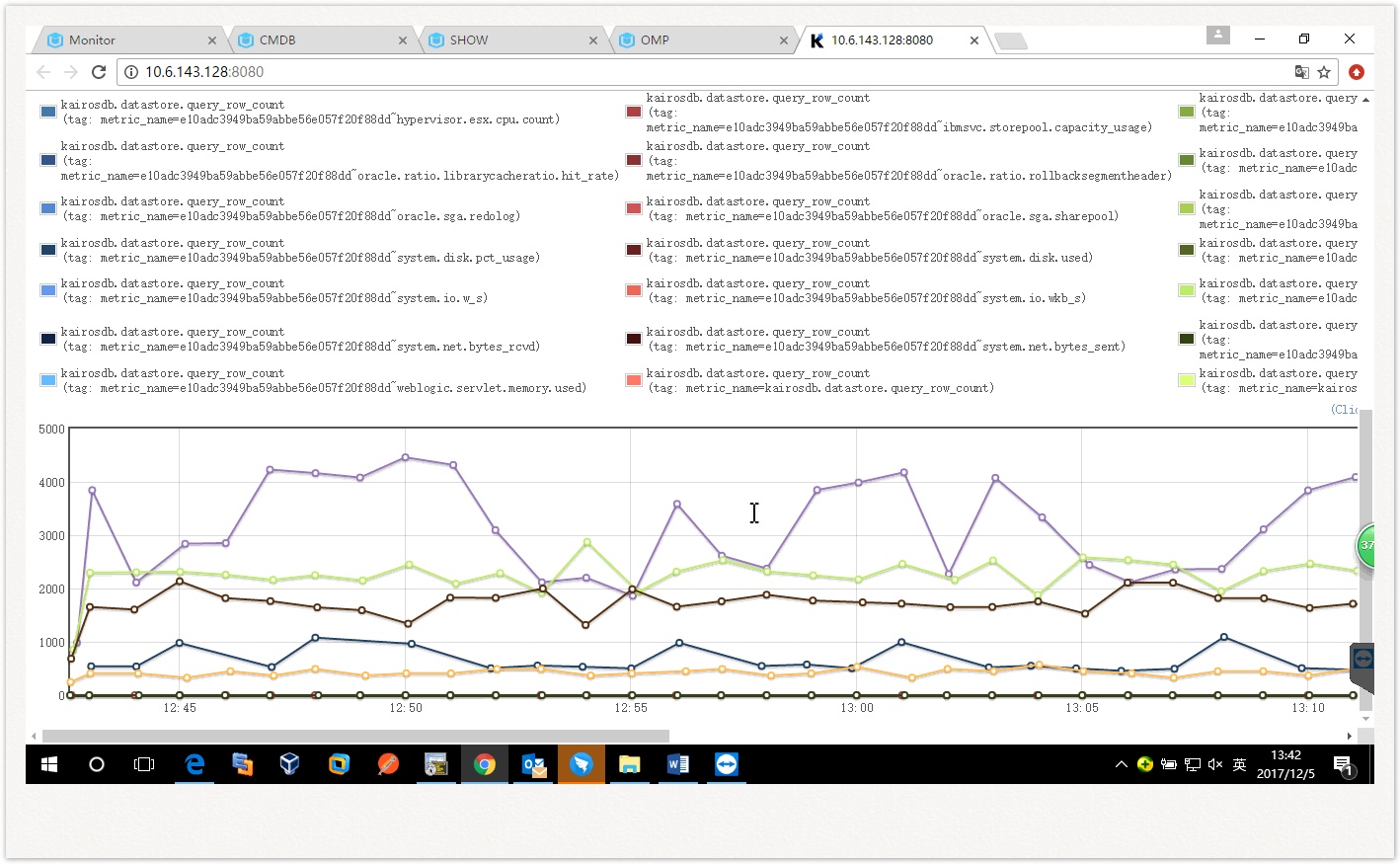
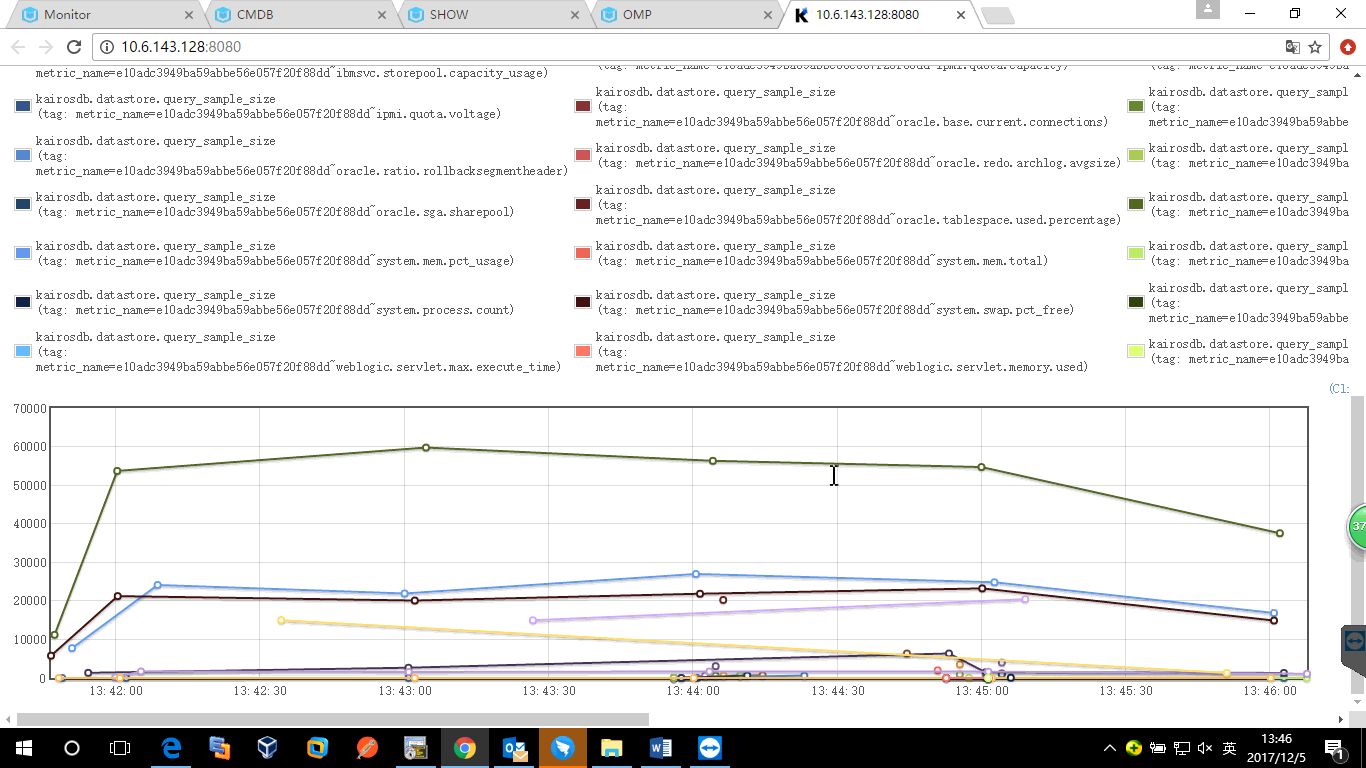
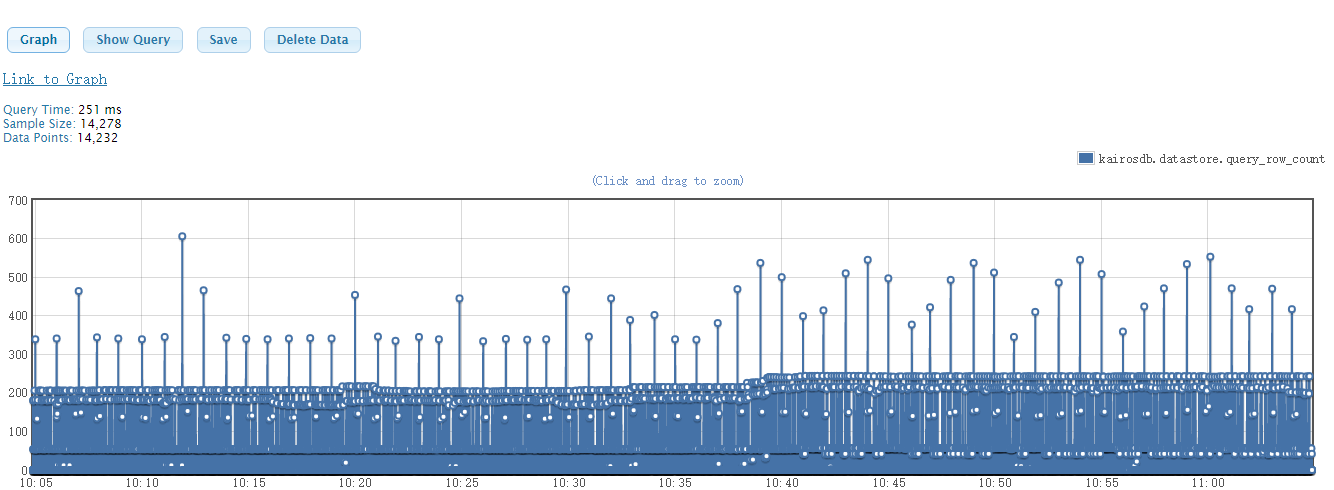
可以看出:
密集查询时,row最大的在4000,大部分比较小,接近1。定时查询时,row在100行以下。
现场400个设备,查询30分钟指标时,理论上应该有大约400430=48000 的元数据,实际查询时,要小于该值。基本都在几百条。
过程:
- 可以看到单Cassandra节点下,kairosdb查询Cassandra最短耗时已经在2S左右,而集群模式下,kairosdb查询Cassandra的最短耗时在200ms
左右,可以看出在低硬件配置下,Cassandra部署集群模式比单机模式的性能提升很大。
- Cassandra刚部署时,查询性能表现优秀,连续写入一个小时数据后,查询性能下降。
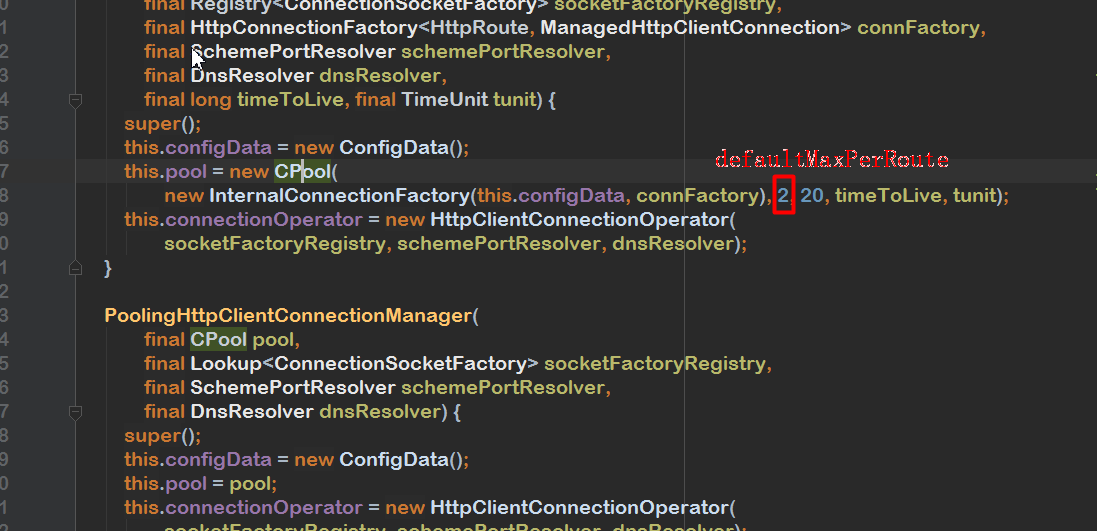
- 2-5组发现kairosdb 查询时间正常, 但指标库查询出现超时,经建飞排查,原因是调用kairosdb client时创建的 http连接 最大数量最2,修改为200后,情况好转。
- 从测试过程可以看到,部分指标库的查询耗时比kairosdb查Cassandra的耗时长很多,查询kairosdb.datastore.queries_waiting
指标,发现kairosdb存在大量等待线程。如下: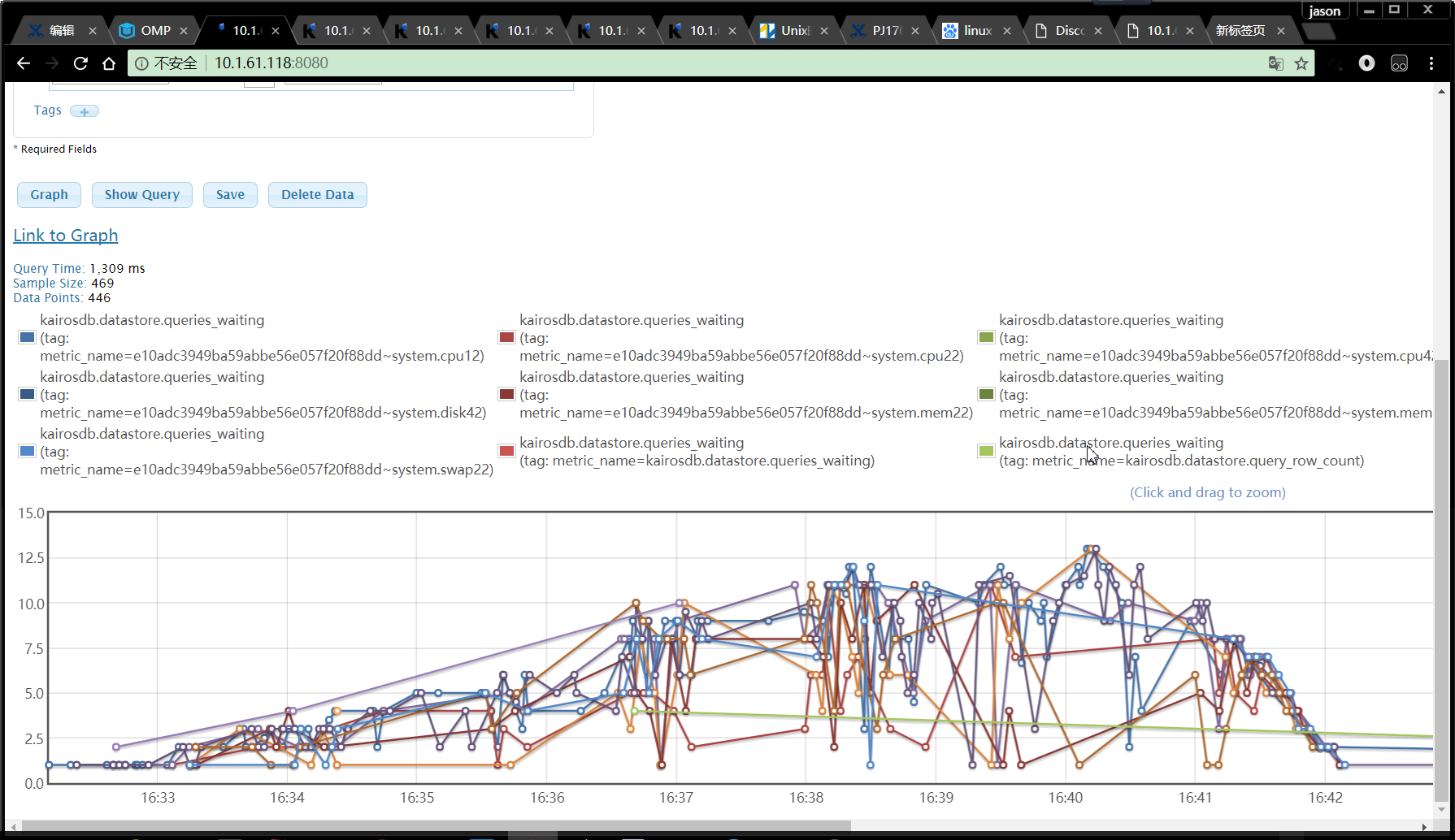
修改
kairosdb 的配置:kairosdb.datastore.concurrentQueryThread ,再次查询,依然会有等待的查询线程。
据此判断,当查询15个指标时,每个指标耗时在2.5S左右时,此硬件配置下的kairosdb性能已达瓶颈,影响因素为CPU核数。当更改部署kairosdb
机器的核数后,性能得到了提升。
- 同样的查询条件下,CPU核数与kairosdb 的concurrentQueryThread 参数一致时,性能最优;且该参数只在kairosdb 查Cassandra较慢(2S以上)时,才会产生影响。
五、结论
1、指标库写性能:
- 由3、5、6组可知,每分钟请求总量一定的情况下,在未到达瓶颈前,并发线程越多,指标写入量越大。
- 由6、8组可知,本机的机器性能并未成为影响指标写入的因素。
- 由6、7和8、9两组可知,在4核16G单节点Cassandra 配置下,请求数在50W/min 左右时,指标库的gateway 模块接收请求已到达瓶颈,为 50W /min 左右。
- 由9、10、11三组可知,在指标写入能力到达瓶颈后,改变并发的线程数,不再产生影响。
- 由9、12组可知,待写入的指标类型量不是影响因素。
- 由15组可知,当指标库写入请求量每分钟到千万级时,会出现redis 内存问题。
- 单指标库、单Cassandra节点下,指标写入能力瓶颈在Cassandra处,为 80W/min;
多指标库、单Cassandra节点下,指标写入能力瓶颈在Cassandra处,为
85W/min;
单指标库、多Cassandra节点下,指标写入能力瓶颈为 100W/min;
多指标库、多Cassandra节点下,指标写入能力瓶颈为
110W/min。
配置预估:
假设现场1个资源每15 S上报100个指标,则每分钟上报400个,若采用单节点Cassandra
配置,在redis集群状况良好的情况下,可支持1750个资源左右,考虑到稳定性可酌情减少资源量或增加配置。
2、指标库读性能:
- 由1、2组可知R12版本指标库在现有配置下,最多支持每分钟30次的查询。
- 由2、3组可知,查询较慢时,每10S钟查询10次,比每5S钟查询5次,查询要快。
- 由2、4组可知,相同的请求量下,同一个指标密集查询2次,比两个指标同时各查一次要慢很多。
- 由1、5组可知,查询的数据量从600到7200,查询的Cassandra row从 77到740,查询耗时基本没有变化,不过Cassandra的资源消耗增加很多。
- 由2、7组可知,kairosdb client 创建的 http连接 最大数量与查询性能十分相关,R13中已调整该参数为200。
- 由6-8、14、15组可知,单Cassandra节点下,指标查询的瓶颈为 90次/分钟,且当 指标库的查询耗时 与
kairosdb查Cassandra的耗时相差不大时,可以维持稳定查询状态,否则指标库查询超时会越来越严重。
- 由8-13、17-19组可知,kairosdb的concurrentQueryThread 参数值与CPU核数一致时,性能最优;且该参数只在kairosdb 查Cassandra较慢(2S以上)时,才会产生影响。
- 由8、16组可知,指标库是否集群模式不是瓶颈。
- 由19、22和20、23两组可知,单kairosdb 8核的查询性能 与双kairosdb 4核基本相同,所以kairosdb 的查询性能与机器的CPU核数有关。
- 由19、24组可知,当前的查询瓶颈在Cassandra 处,Cassandra 集群的查询性能是单节点的10倍。
- 由24-29组可知,Cassandra集群下,查询性能瓶颈为1400次/分钟,当查询到1500次/分钟时,kairosdb出现瓶颈,等待查询线程不断增加。
- 由30、31组可知,当Cassandra写入一段时间数据后,指标查询性能下降很多。
linux 进程 性能监控
背景
进行性能测试,需要统计 kairosdb 的性能随时间的变化情况。
分析
考虑过以下方法
sar 命令:可以检测机器的各项性能,但不能看进程的性能占用信息
top:可以监控到进程的性能信息,但没有趋势图
jvisualvm:可以监控到进程的性能信息,有趋势图;但可监控的时间范围受限、不能统计各项状态信息。如下:

最终发现jconsole 可以完美实现这个需求。之前只是感觉jconsoleg功能不如jvisualvm强大,所以没有去看…
jconsole 使用方法:
修改远程机器JDK配置文件 (我这里远程机器是linux).
a.进入JAVA_HOME\jre\lib\management\目录
b.拷贝jmxremote.password.template这个文件到当前目录, 并改名为 jmxremote.password
c.打开jmxremote.password文件,去掉 # monitorRole QED 和 # controlRole R&D 这两行前面的注释符号修改远程机器上需要被监控的程序的启动脚本:
JAVA_OPTS="-Djava.rmi.server.hostname=10.1.61.117 -Dcom.sun.management.jmxremote.port=18999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"启动脚本 的java 命令后加上 $JAVA_OPTS 参数。
本地建立连接,如下:

界面如下:

更多功能可自行尝试
可以保存统计数据 到本地(CSV 文件),如下:

总结
需求解决 (真是踏破铁鞋无觅处…)
Dubbo Telnet 命令
目录 (Table of Contents)
从 2.0.5 版本开始,dubbo 开始支持通过 telnet 命令来镜像服务治理。
login
telnet localhost 20880(dubbo或服务端口)

status
- status: 显示汇总状态,该状态将汇总所有资源的状态,当全部 OK 时则显示 OK,只要有一个 ERROR 则显示 ERROR,只要有一个 WARN 则显示 WARN
- status -l: 显示状态列表
见上图
ls
显示服务列表、方法列表、参数等
- ls: 显示服务列表
- ls -l: 显示服务详细信息列表
- ls XxxService: 显示服务的方法列表
- ls -l XxxService: 显示服务的方法详细信息列表

ps
显示服务端口列表,可用来查看服务是否已成功注册
- ps: 显示服务端口列表
- ps -l: 显示服务地址列表
- ps 20880: 显示端口上的连接信息
- ps -l 20880: 显示端口上的连接详细信息
见上图
trace
跟踪服务任意方法的调用情况
- trace XxxService: 跟踪 1 次服务任意方法的调用情况
- trace XxxService 10: 跟踪 10 次服务任意方法的调用情况
- trace XxxService xxxMethod: 跟踪 1 次服务方法的调用情况
- trace XxxService xxxMethod 10: 跟踪 10 次服务方法的调用情况

invoke
调用服务的方法,通过该命令可直接调试方法。
- invoke XxxService.xxxMethod({“prop”: “value”}): 调用服务的方法
- invoke xxxMethod({“prop”: “value”}): 调用服务的方法(自动查找包含此方法的服务)

more
更多 Dubbo Telnet 命令请参阅:Telnet 命令参考手册
Cassandra 常用命令合集
目录 (Table of Contents)
文中Cassandra 安装在/opt 目录下,具体执行命令需根据自己的Cassandra安装目录进行调整。
Cassandra 版本为 3.5。
修改Cassandra 最大可用内存大小
Cassandra 默认最大可用内存和初始内存大小(-Xmx 、-Xms )为 4G ,通常情况下偏小。
修改最大内存大小可直接修改 cassandra/conf/cassandra-env.sh 中 MAX_HEAP_SIZE 参数:MAX_HEAP_SIZE="4G"
cassandra 有两种GC策略,系统内存在14G以上,推荐使用 G1策略。默认使用的是CMS策略。参阅Tuning Java resources
登录CQL、查看版本
登录:/opt/cassandra/bin/cqlsh [ip] -u [username] -p [passwd]
查看版本:cqlsh>show version

查看墓碑数据总量
没有直接查看墓碑数量的好方法,可在CQL 中开启tracing,执行查询时,会提示具体表含有多少墓碑数据:

修复表
修复表可以手动同步各个节点的数据(包括墓碑数据),需在各个节点分别执行
/opt/cassandra/bin/nodetool repair kairosdb string_index;
压实数据
墓碑数据过多会影响Cassandra性能。压实数据,可消除墓碑数据。压实前,需进行表数据的修复,以防删除数据恢复。
- 手动压实:
/opt/cassandra/bin/nodetool compact kairosdb string_index
开启自动压实(默认已开启):
/opt/cassandra/bin/nodetool enableautocompaction修改表的压实策略:
ALTER TABLE kairosdb.string_index WITH compaction = {'class' : 'SizeTieredCompactionStrategy', 'min_threshold' : 6 };
- 修改自动压实周期:
默认压实时间为864000,即10天,修改为一天:alter table kairosdb.string_index with GC_GRACE_SECONDS = 86400;
关于压实策略,请参阅:How is data maintained
查看当前压实操作状态和历史压实纪录
/opt/cassandra/bin/nodetool compactionstats;
/opt/cassandra/bin/nodetool compactionhistory;

查看表的状态
/opt/cassandra/bin/nodetool cfstats kairosdb.data_points 或
/opt/cassandra/bin/nodetool tablestats kairosdb.data_points;

Cassandra 线程池的使用统计信息
Cassandra基于分阶段事件驱动架构(SEDA)。Cassandra将不同的任务分成由消息服务连接的很多阶段。每个阶段都有一个队列和一个线程池。如果下一个阶段太忙,Cassandra会备份队列,并将导致性能瓶颈。
/opt/cassandra/bin/nodetool tpstats;

其他
更多 cassandra命令请参阅:The nodetool utility 、Apache Cassandra
记一次store 指标库 线上故障的排查
目录 (Table of Contents)
环境
统计局,三个节点配置一样:
- 内存:500+G
- CPU:4*13 core
Cassandra 、kaiorsdb 、指标库都是以集群模式部署在三台机器上。
问题&分析&解决
问题1
统计局 monitor线上环境 统计报表和仪表盘部分加载缓慢,加载时间在8秒左右。

分析
首先看了指标库的reader 模块日志,发现query 大量timeout异常。
1 | 17-09-22 14:12:29.208 WARN [DubboServerHandler-10.6.143.124:7513-thread-576] [c.a.d.rpc.filter.TimeoutFilter] [DUBBO] invoke time out. method: queryarguments: [e10adc3949ba59abbe56e057f20f88dd, DatapointQuery{metric='system.mem.pct_usage', time=DatapointQueryTime{start=1506060435275, end=1506060735275, interval=1, interval_unit='seconds', aggregator=AVG, align_start_time=false, align_sampling=false}, tags={tenantId=e10adc3949ba59abbe56e057f20f88dd}, groupBy=DatapointQueryGroupBy{tagKeys=[object]}, useCache=false}] , url is dubbo://10.6.143.124:7513/uyun.indian.reader.api.ReaderService?anyhost=true&application=indian-reader&default.accepts=1000&default.threadpool=cached&default.threads=500&default.timeout=5000&dubbo=2.8.4.170831&generic=false&interface=uyun.indian.reader.api.ReaderService&methods=queryByResId,query,queryAllMetrics,queryTags&pid=20707&revision=api&serialization=kryo&side=provider×tamp=1505982696415, invoke elapsed 6361 ms., dubbo version: 2.8.4.170831, current host: 10.6.143.124 |
解决
query 使用的 kairosdb的读方法。kairosdb wiki上指出,当指标的 tag/value 组合太大时,查询时将变得非常缓慢。
而monitor报表 每次查询需要汇聚一天的数据。一天的指标数据量和读取时间如下:
一种解决方法是使用TScached进行读取,tscached 是kairosdb 的一个缓存代理,加载速度可以是kairosdb的100倍(这是它自己说的,感觉有点夸张了)。
指标库之前已经配置过 TScached,后来停用了。重新启用后,报表的加载速度明显加快,不再报超时。
1 | 17-09-28 10:01:26.123 INFO [reporter-thread-1 ] [u.i.method.elapsedtime.report ] ********************* start report 2017-09-28 09:56:26 to 2017-09-28 10:01:26 ********************* |
问题2
query 方法速度上来之后,发现queryAllMetrics 方法出现超时现象,按问题1的解决办法处理后,发现仍有问题,后改用读redis 缓存的方式后,暂时解决。
但Cassandra的资源消耗仍比较大


分析
查看Cassandra system日志后发现 kairosdb.data_points 表中存在大量tombstone(墓碑)数据警告,严重影响了Cassandra性能。需对Cassandra 进行数据compact(压实)操作,以清除墓碑数据。
在对数据进行压实操作之前,需要先repair(修复)。
1 | WARN [SharedPool-Worker-30] 2017-09-26 15:48:50,818 ReadCommand.java:481 - Read 1024 live rows and 22072 tombstone cells for query SELECT value FROM kairosdb.data_points WHERE key = 65313061646333393439626135396162626535366530353766323066383864647e73797374656d2e6e65742e62797465735f72637664000000015dc970d000000d6b6169726f735f646f75626c656465766963653d6962313a686f73743d646d3031646261646d30342e73746174732e676f762e636e3a69703d31302e362e3133342e38303a6f626a6563743d3539383763643931633633396438613830633433653631383a74656e616e7449643d65313061646333393439626135396162626535366530353766323066383864643a AND column1 >= 00000000 AND column1 <= 9dd94 (see tombstone_warn_threshold) |
在Cassandra中,一切都是写入,包括逻辑删除数据,当你删除一条数据时,其实是给这条数据进行update,给它update上一个标识,就是一个墓碑标识。 当Cassandra集群在不同节点之间同步删除信息的时候,也会用到Tombstones(墓碑),可以说墓碑是一种允许Cassandra快速写入的机制。
关于Cassandra 如何维护数据,可参考 Cassandra 数据维护官方文档
解决
具体压实步骤如下:
- cassandra 默认压缩周期为10天,首先将压缩周期设为1天,设置 gc_grace_seconds 参数,
登录Cassandra:
1 | ./cqlsh host -u user -p pswd |
设置kairosdb的表的压缩周期设为 一天(86400 s):
1 | alter table kairosdb.string_index with gc_grace_seconds = 86400;alter table kairosdb.data_points with GC_GRACE_SECONDS = 86400;alter table kairosdb.row_key_index with GC_GRACE_SECONDS = 86400; |
CREATE TABLE kairosdb.string_index (
key blob,
column1 text,
value blob,
PRIMARY KEY (key, column1)
) WITH COMPACT STORAGE
AND CLUSTERING ORDER BY (column1 ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {‘keys’: ‘ALL’, ‘rows_per_partition’: ‘NONE’}
AND comment = ‘’
AND compaction = {‘class’: ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’, ‘max_threshold’: ‘32’, ‘min_threshold’: ‘4’}
AND compression = {‘chunk_length_in_kb’: ‘64’, ‘class’: ‘org.apache.cassandra.io.compress.LZ4Compressor’}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 86400
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 1.0
AND speculative_retry = ‘NONE’;
1 |
|
nodetool repair kairosdb row_key_index
nodetool repair kairosdb string_index
nodetool repair kairosdb data_points1
2
3
4
*此处运行修复时,三个节点的data_points表由于数据太大,一直没有完全修复成功(some repair failed )。由于数据量较大,且接受删掉的数据再次恢复,此处采取的措施是忽略该表。
3. 修复完后再分别进行压实操作:
nodetool compact kairosdb row_key_index
nodetool compact kairosdb string_index
nodetool compact kairosdb data_points1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
压实操作可用`nodetool compactionstats` 和 `nodetool compactionhistory`分别查看当前和历史的压实造作;
{% asset_img compactionstats.png 压实状态 %}
4. 开启自动压实操作(默认已开启):`nodetool enableautocompaction`
操作完后,Cassandra 会自动压缩一些其他表的数据。结束后,Cassandra 日志中data_points表 墓碑警告记录墓碑数量大幅变小,可以发现Cassandra对资源的占用变到正常水平。
#### 其他问题
1. cassandra 日志报:
``
INFO [IndexSummaryManager:1] 2017-09-28 08:16:56,278 IndexSummaryRedistribution.java:74 - Redistributing index summaries
INFO [SharedPool-Worker-1] 2017-09-28 08:19:46,973 NoSpamLogger.java:91 - Maximum memory usage reached (536870912 bytes), cannot allocate chunk of 1048576 bytes
``
2. Dubbo 消费者报:No provider available for the service。
#### 分析&解决
1. 调查得知,原因是file_cache_size_in_mb较小,文档中描述该参数是用来读[SSTables](https://stackoverflow.com/questions/2576012/what-is-an-sstable)(Sorted Strings Table , is a file of key/value string pairs, sorted by keys)的缓冲区:
>file_cache_size_in_mb :(Default: Smaller of 1/4 heap or 512) Total memory to use for SSTable-reading buffers.
调到1024 (M)后,不再报该问题
2. 服务注册不到zookeeper 上,猜测可能是机器IO负载太大。
执行`netstat -nat | awk '{print $6}' | sort | uniq -c | sort -n` ,可以看到 CLOSE_WAIT 连接太多:
[root@Uyun-DB2 logs]# netstat -nat | awk ‘{print $6}’ | sort | uniq -c | sort -n
1 established)
1 Foreign
2 TIME_WAIT
47 LISTEN
1088 ESTABLISHED
3314 CLOSE_WAIT`
netstat -nat | grep CLOSE_WAIT 后,发现是kairosdb 造成的(猜测是之前Cassandra负载太大造成 ),强行重启kairosdb 后,再启动指标库,服务正常。
其他
kairosDB 作者建议采用DateTieredCompactionStrategy (DTCS)压实策略,参考 kairosDB Issue 23。需要进一步研究。
还是会有 Cassandra 占CPU较高的现象,但日志正常,需要进一步研究。