推荐阅读时间:5分钟
引言
先来看一个问题,假设现在有范围为 1-10 亿的 11 亿个 int 型整数,如何排除掉其中的重复数字?int 占 4 个字节,可以表示 -2,147,483,648 ~ +2,147,483,647 的数据。
所以一般的思路是会将这 11 亿个数作为 int 型数据存到一个 HashSet 集合中进行去重。但是,这样会存在一个问题。我们知道 1GB=1024KB=1024 1024Byte,那么 10亿 4Byte 将占用接近 4GB 的内存,这将是极大的性能浪费,很可能会影响程序的健康运行。
思路
我们可以考虑用”位映射(BitMap)”来解决这个问题。试想一下,如果我们有一个位数组(bit[n]),那么我们可以用 bit[i] 来表示 0-n 中对应的数字,每个元素有 1 和 0 两个取值,分别代表该数字存在与否。这样一来,我们记录一个数字只需要一个 bit,相对于之前的 int 类型(32 bit),整整缩小了 32 倍的存储大小(4GB/32=125MB)!
扩展一下,当我们需要记录每个数字出现次数是否超过 2 次时,可以使用连续的两位来记录一个数字:一位用来记录是否出现,另一位用来记录是否超过 2 次。
不过,Java 中无法创建 bit 数组,我们可以使用 int 或 long 数组来实现这个目的。建立一个 int 数组 int[n],int[0] 记录了 0-31,int[1] 记录了 32-63 …… 依此类推。
Java BitSet
Java 中有一个 BitSet 类,从命名就可以看出它是用来存储去重的位元素集合,它还支持 and、or 等位运算。用来解决文章开头的问题非常合适,方式如下:
1 | public class BitSetStudy { |
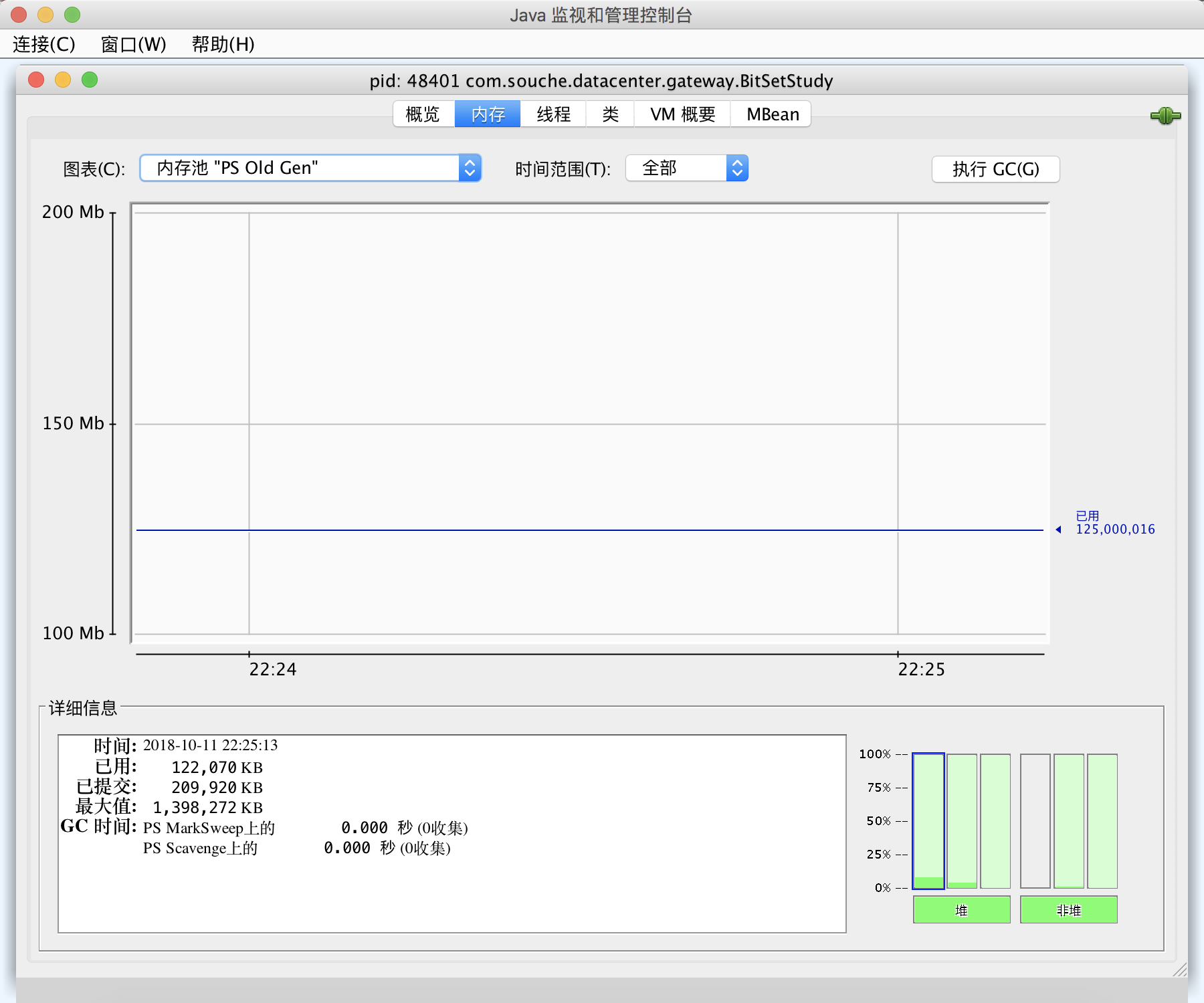
打开 jconsole,可以看到存储了 bitset 对象的老年代所占用的内存稳定在 125MB 左右。
关于 BitSet 的 and、andNot、or、xor 操作:
1 | public static void main(String[] args) { |
结果如下:1
2
3
4
5
6bitSet is : {2, 3, 4, 5} , and bitSet1 is: {4, 5, 6, 7}
run bitSet.XMethod(bitSet1) , result is :
and:{4, 5}
andNot:{2, 3}
or:{2, 3, 4, 5, 6, 7}
xor:{2, 3, 6, 7}
自己实现 BitMap
Java 的 BitSet 使用起来存在局限性,我们可以参考 BitSet 实现自己的 BitMap 来扩展应用场景。核心还是通过 int/long 数组元素的位来记录有序数据,一个实现如下:
1 | public class BitMap { |
实现了核心的存储结构、set 和 get 方法。
布隆过滤器(Bloom Filter)
了解完 BitMap,我们掌握了一种处理大量连续数据的好方法。现在继续扩展一下,现在如果我们要记录的是海量的分布很不均匀的数据,如果继续用 BitMap 的方式,将会浪费大量的存储空间,或者数据量已经大到使用 BitMap 的方式,仍然会浪费大量的内存空间。面对这两种情情况时,我们可以考虑使用布隆过滤器。
布隆过滤器核心是对一个 key 使用多个 hash 函数求出多个值,将这些值散列在一个有限的数组中,这样,当这些 hash 函数求出的值都符合预期就认为该 key 存在;若只要存在 hash 函数的值不符合,就可以确定它不存在。在某些场景下,这种方法效果非常好。图示如下:
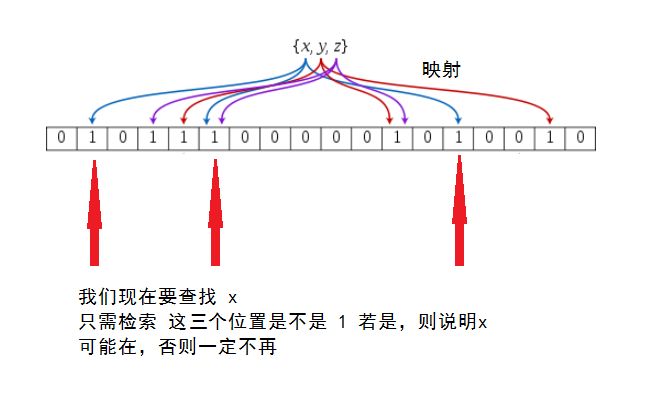
可以看出来,这种方法存在一定误差,不过误差几率可以通过增加 hash 函数和散列数组大小来减小。还有一个问题就是,当某个 key 被删除后,不能直接在散列表中将对应的 value 去掉,因为可能会影响其他 key。针对这个问题,我们可以维护一个黑名单,每次计算 hash 前,先判断 key 是否在黑名单中,有则表示该 key 已删掉。
套=140套 呵呵😅")

——%20compute/IMG_0011.JPG "故乡的月")
——%20compute/IMG_0007.JPG)