*本文是从公司内网KB转过来的,格式有点混乱懒得改了QAZ~~
目录 (Table of Contents)
- FAQ
- 一、测试目的
- 二、测试环境
- 三、测试方法
- 四、测试结果
- 写:
- 读:
- 五、结论
- 1、指标库写性能:
- 2、指标库读性能:
FAQ
1.写入能力:多少个15秒监控周期的主机,或180秒监控周期的网络设备的数据写入
假设现场1个资源每15 S上报100个指标,则每分钟上报400个,
若部署单节点Cassandra,在redis集群状况良好的情况下,每分钟可写入80W个指标,可支持800000/400=2000个资源左右;
若部署Cassandra 集群,每分钟可写入110W个指标,可支持1100000/400=2750个资源左右;
考虑到稳定性可酌情减少资源量或增加配置。
2.读出能力:每秒完成指定数据点数查询的TPS性能峰值,以便预测可以支持什么数量的仪表盘
在三台4C*16G的Cassandra节点的配置下,稳定查询的前提下,每分钟至少400条并发请求(每条请求至少6000条元数据,大约为15分钟的数据)。
一、测试目的
测试在指定硬件条件下,指标库写入能力与读取能力。
二、测试环境
| ip | cpu | 内存 | 磁盘 | 用途 | 备注 |
|---|---|---|---|---|---|
| 个人电脑 | 4核 | 16G | 部署jmeter | ||
| 10.1.53.37 | 6核 | 8G | 部署jmeter-server | 通过jmeter来发送测试请求, 这些机器同时部署着其他产品。 | |
| 10.1.53.38 | 4核 | 16G | |||
| 10.1.53.65 | 4核 | 8G | |||
| 10.1.61.10 | 4核 | 24G | |||
| 10.1.53.39 | 4核 | 16G | 指标库、ES、租户等组件 | 该机器主要用来部署指标库 | |
| 10.1.61.117 | 4核 | 16G | 38G | kairosdb、omp等 | kairosdb 堆内存为默认的3g |
| 10.1.61.118 | 4核 | 16G | 38G | Cassandra | kairosdb 堆内存为为默认的4g, 计算公式 max(min(1/2 ram, 1024MB),min(1/4 ram, 8GB)) |
三、测试方法
测试工具为Jmeter,通过调用指标库相应的openApi测试,用jconsole 监控进程占用资源变化。
四、测试结果
写:
Ramp-up Period 决定多长时间启动所有线程。如果使用10个线程,ramp-up period是100秒,那么JMeter用100秒使所有10个线程启动并运行。每个线程会在上一个线程启动后10秒(100/10)启动。
monitor 指标上报的频率是15S一次,故此处从 以15S/s 的频率启动一个上报线程开始测试。
如组1,测试逻辑为:
每15秒启动一个线程,单个线程每次上报25个指标,重复上报500次,每分钟指标写入请求次数为5W条。
jmeter-server为1,表示只在本机运行测试;若为4,表示在4个机器上同时对指标库发起请求测试。
1.kairosdb 自带写入统计指标:
kairosdb.metric_counters - Counts the number of data points received since the last
report. Tags are used to separate one metric from another.(统计自上次上报后接收的数据量。标签用于区分指标。)
kairosdb 统计结果:
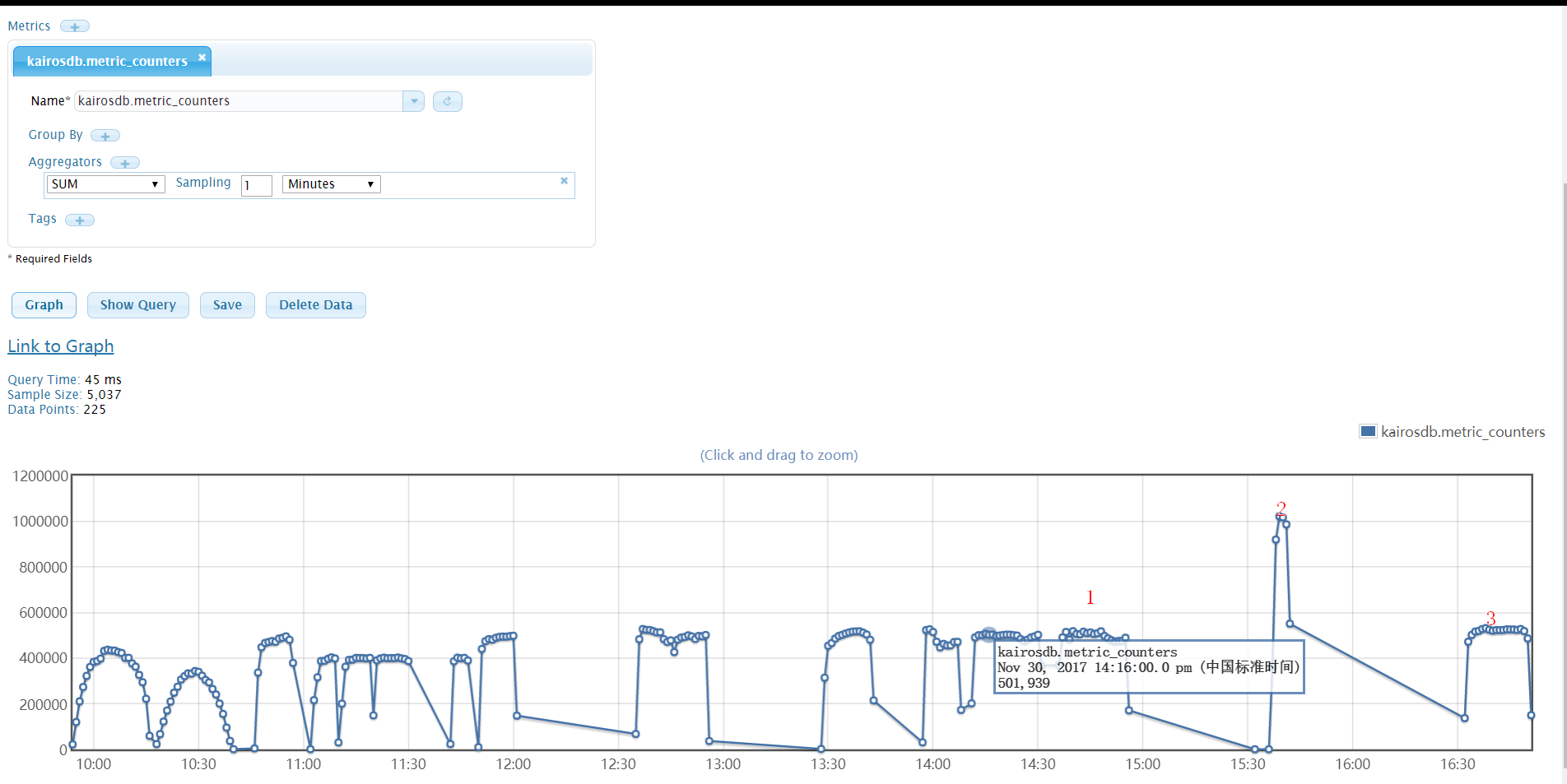
“1”处为组别12的测试结果,“2”处为直接调用kairosdb restApi 写入接口,“3”处为组别14 的结果。结果与指标库的统计日志一致。
2.时间有限,每组测试时间间隔较短,因此可能会对CPU、内存以及Cassandra状态产生影响,使结果不够准确。
注:
【1】:指标库redis 报内存不够,异常: Can’t save in background: fork: Cannot allocate memory
【2】:短时间插入大量指标会导致未压实的sstable数据太多,压实进程报可用磁盘空间不足,重新压实…恶性循环。
1 | <![CDATA[[root@localhost data_points-1e09be40c3c811e7977aa147ea7baf03]# /opt/cassandra/bin/nodetool compactionstats -H |
Cassandra报异常:
1 | <![CDATA[WARN [CompactionExecutor:46] 2017-11-28 22:26:29,785 CompactionTask.java:91 - insufficient space to compact all requested files BigTableReader(path='/opt/dbdata/cassandra/data/kairosdb/data_points-1e09be40c3c811e7977aa147ea7baf03/ma-216-big-Data.db'), BigTableReader(path='/opt/dbdata/cassandra/data/kairosdb/data_points-1e09be40c3c811e7977aa147ea7baf03/ma-237-big-Data.db') |
解决方法:
1、增大磁盘空间、
2、直接删除同一编号的sstable 大文件
3、重装Cassandra
多节点写:
1.通过观察发现,写的瓶颈在指标库的gateway,然后增加多节点的测试如下:
- 开启一个gateway、一个writer模块后,指标写入能力在 50W/分钟;
- 开启三个gateway、一个writer模块后,指标写入能力在 80W/分钟;
- 开启三个三个gateway、三个writer 模块后,指标写入能力在 85W/分钟。
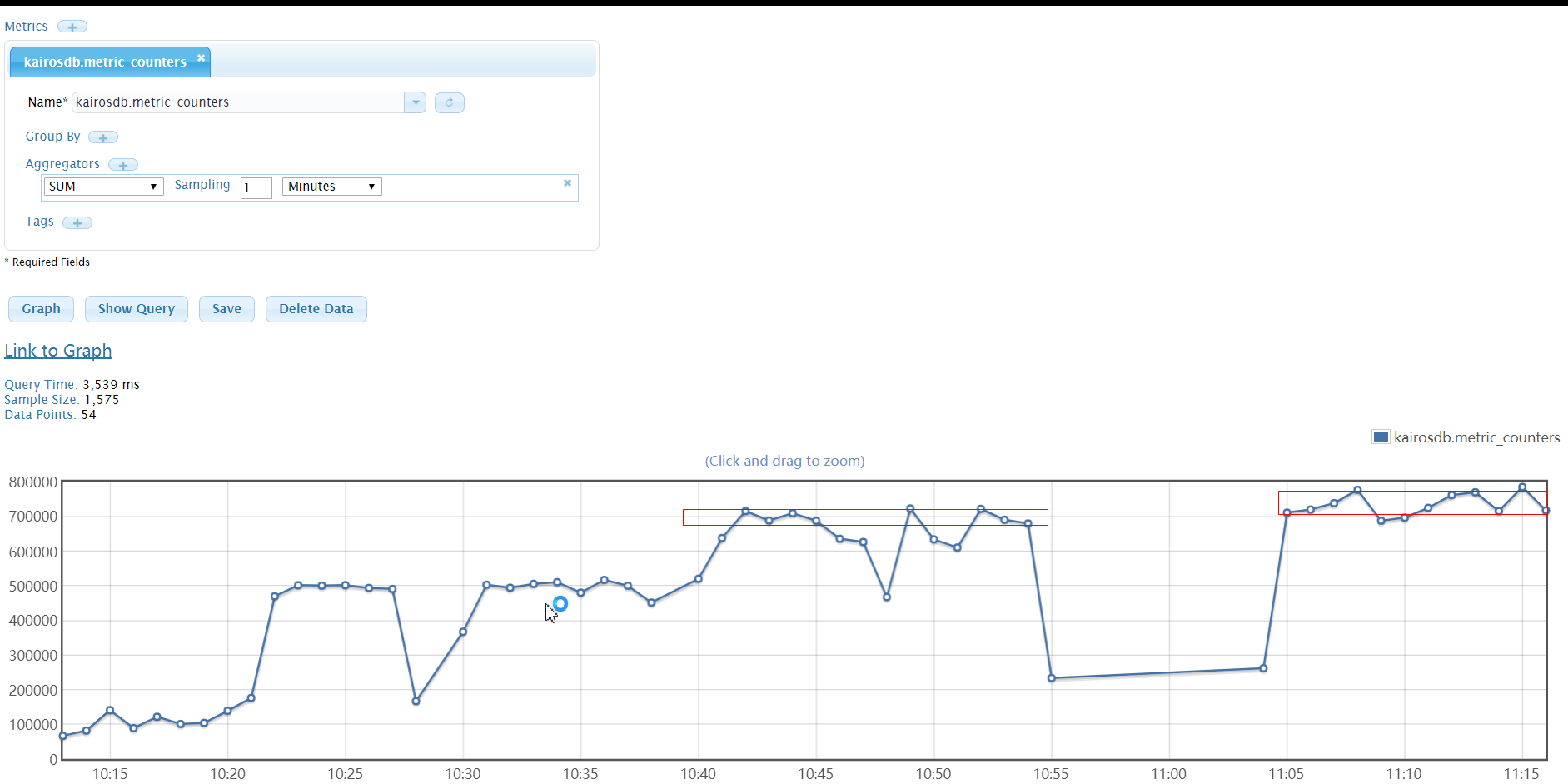
2.当部署Cassandra集群(3个节点)后,指标写入能力可以再次提升,开启三个gateway、一个writer模块,指标写入能力在 100W/分钟 ,此状态下可持续写入四个小时,期间redis会报内存不够的异常。
另外,当指标库写入在满载的情况下,指标的读取能力会受到很大影响,且写入也会偶尔报连接超时现象。
读:
指标的查询,其实是kairosdb去查Cassandra中数据。因此kairosdb查Cassandra的速度才是关键因素。而查Cassandra数据的速度,跟查询的Cassandra的row数量、元数据量等因素相关。
要模拟读取测试,就需要先调查现场实际查询的row和元数据大小。
统计局的统计如下:
上图为密集查询30分钟内指标时,从Cassandra中查询的row的行数;
中图为密集查询30分钟内指标时,从Cassandra中查询的元数据的数量;
下图为定时查询时row的行数。
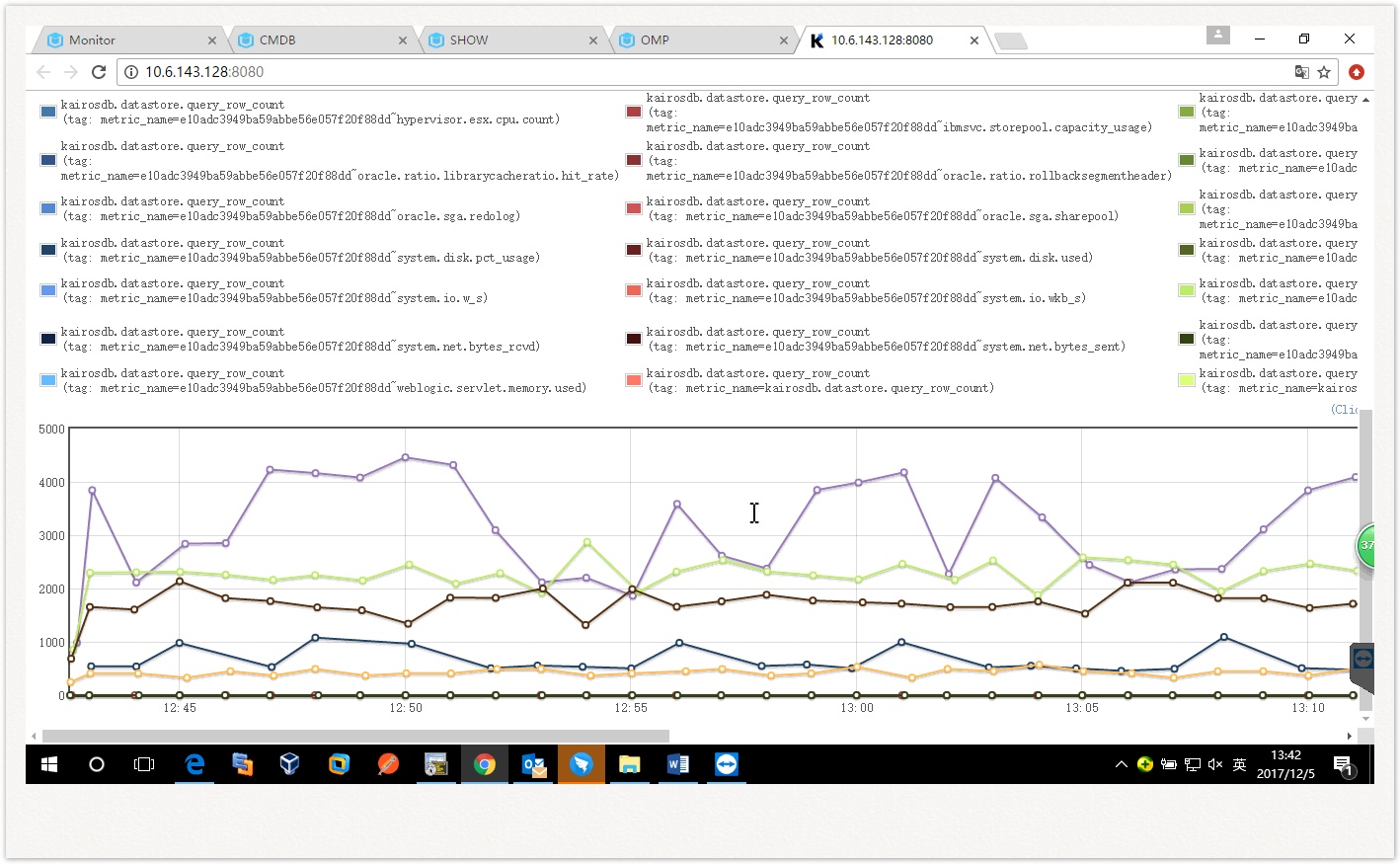
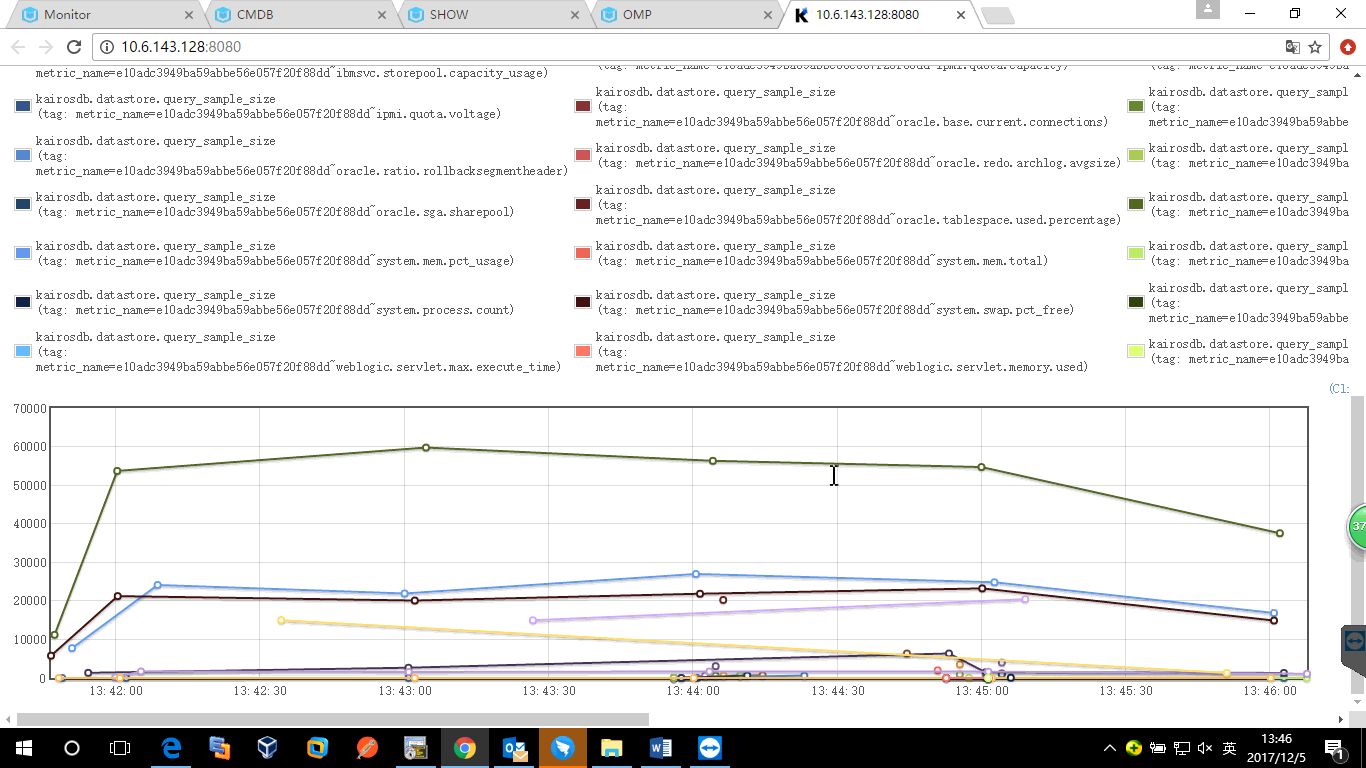
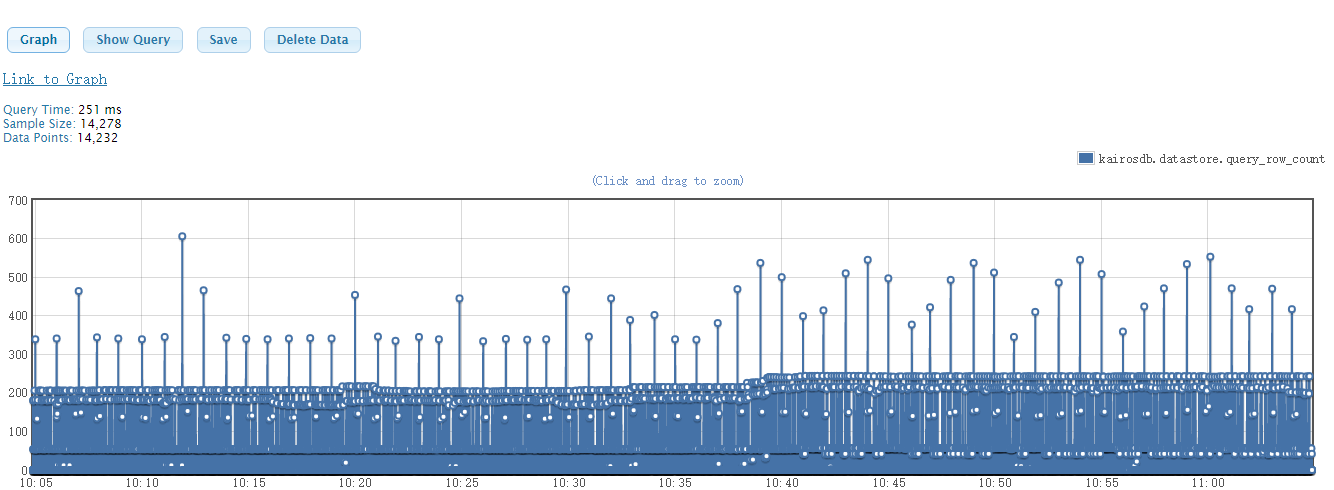
可以看出:
密集查询时,row最大的在4000,大部分比较小,接近1。定时查询时,row在100行以下。
现场400个设备,查询30分钟指标时,理论上应该有大约400430=48000 的元数据,实际查询时,要小于该值。基本都在几百条。
过程:
- 可以看到单Cassandra节点下,kairosdb查询Cassandra最短耗时已经在2S左右,而集群模式下,kairosdb查询Cassandra的最短耗时在200ms
左右,可以看出在低硬件配置下,Cassandra部署集群模式比单机模式的性能提升很大。
- Cassandra刚部署时,查询性能表现优秀,连续写入一个小时数据后,查询性能下降。
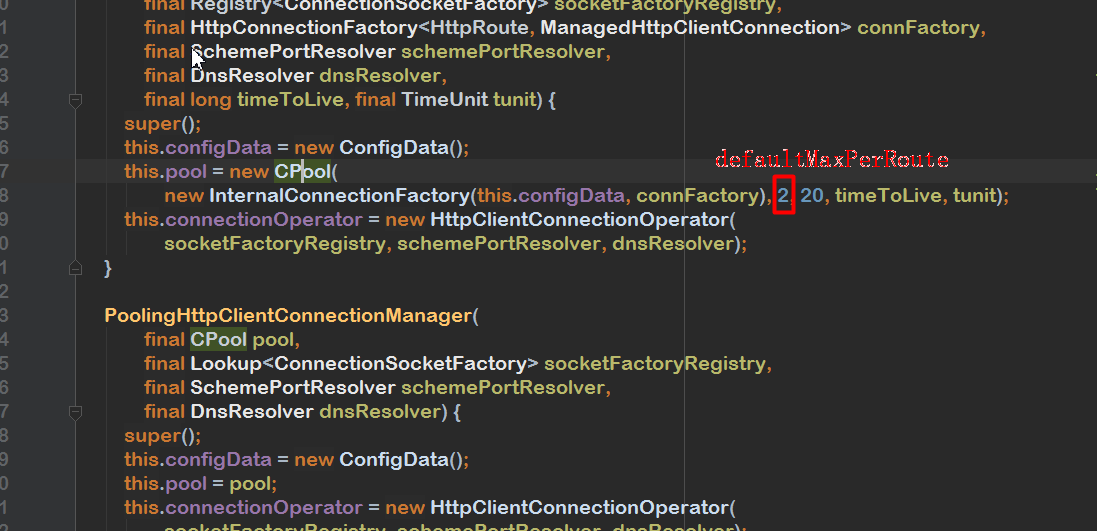
- 2-5组发现kairosdb 查询时间正常, 但指标库查询出现超时,经建飞排查,原因是调用kairosdb client时创建的 http连接 最大数量最2,修改为200后,情况好转。
- 从测试过程可以看到,部分指标库的查询耗时比kairosdb查Cassandra的耗时长很多,查询kairosdb.datastore.queries_waiting
指标,发现kairosdb存在大量等待线程。如下: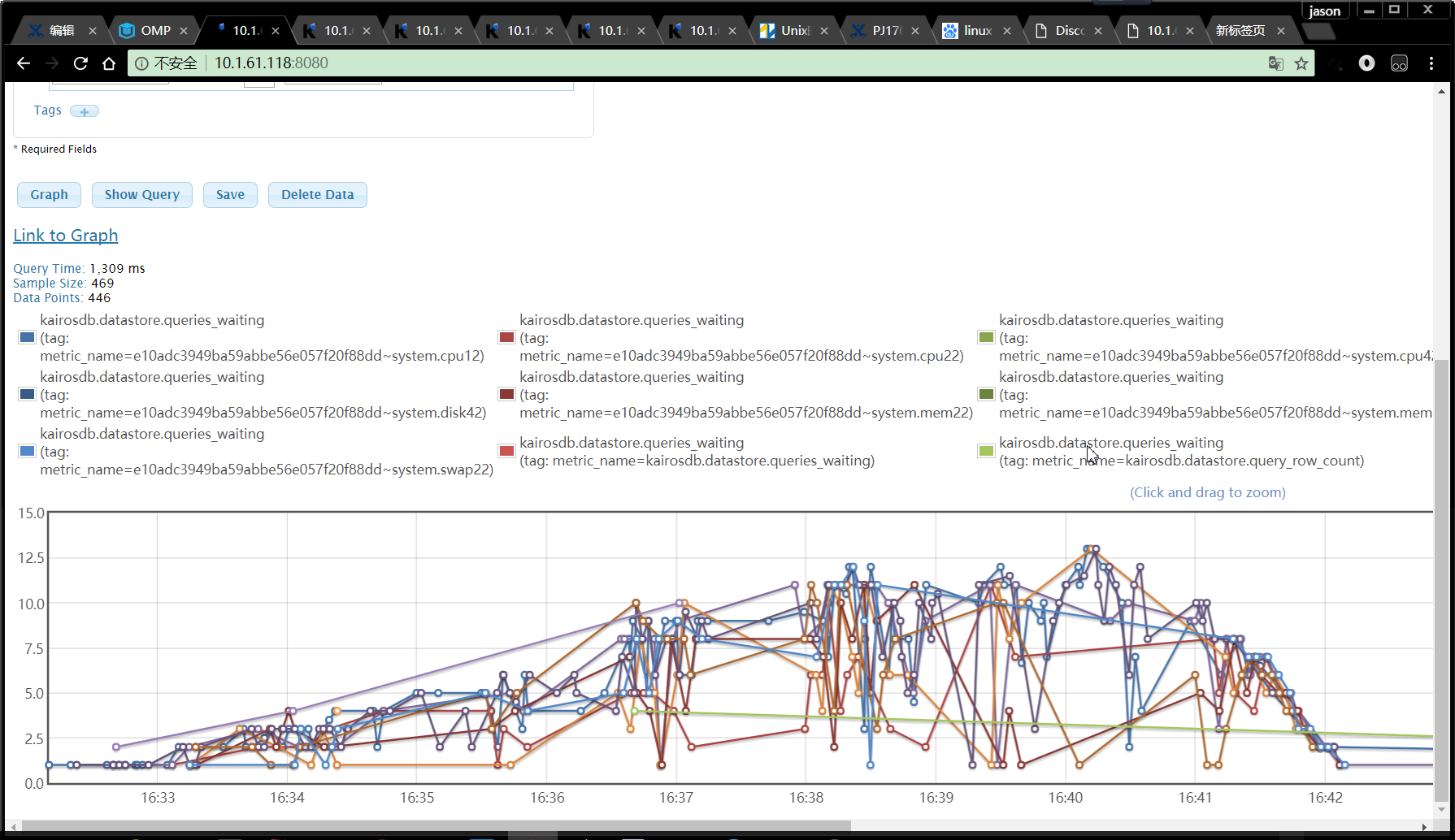
修改
kairosdb 的配置:kairosdb.datastore.concurrentQueryThread ,再次查询,依然会有等待的查询线程。
据此判断,当查询15个指标时,每个指标耗时在2.5S左右时,此硬件配置下的kairosdb性能已达瓶颈,影响因素为CPU核数。当更改部署kairosdb
机器的核数后,性能得到了提升。
- 同样的查询条件下,CPU核数与kairosdb 的concurrentQueryThread 参数一致时,性能最优;且该参数只在kairosdb 查Cassandra较慢(2S以上)时,才会产生影响。
五、结论
1、指标库写性能:
- 由3、5、6组可知,每分钟请求总量一定的情况下,在未到达瓶颈前,并发线程越多,指标写入量越大。
- 由6、8组可知,本机的机器性能并未成为影响指标写入的因素。
- 由6、7和8、9两组可知,在4核16G单节点Cassandra 配置下,请求数在50W/min 左右时,指标库的gateway 模块接收请求已到达瓶颈,为 50W /min 左右。
- 由9、10、11三组可知,在指标写入能力到达瓶颈后,改变并发的线程数,不再产生影响。
- 由9、12组可知,待写入的指标类型量不是影响因素。
- 由15组可知,当指标库写入请求量每分钟到千万级时,会出现redis 内存问题。
- 单指标库、单Cassandra节点下,指标写入能力瓶颈在Cassandra处,为 80W/min;
多指标库、单Cassandra节点下,指标写入能力瓶颈在Cassandra处,为
85W/min;
单指标库、多Cassandra节点下,指标写入能力瓶颈为 100W/min;
多指标库、多Cassandra节点下,指标写入能力瓶颈为
110W/min。
配置预估:
假设现场1个资源每15 S上报100个指标,则每分钟上报400个,若采用单节点Cassandra
配置,在redis集群状况良好的情况下,可支持1750个资源左右,考虑到稳定性可酌情减少资源量或增加配置。
2、指标库读性能:
- 由1、2组可知R12版本指标库在现有配置下,最多支持每分钟30次的查询。
- 由2、3组可知,查询较慢时,每10S钟查询10次,比每5S钟查询5次,查询要快。
- 由2、4组可知,相同的请求量下,同一个指标密集查询2次,比两个指标同时各查一次要慢很多。
- 由1、5组可知,查询的数据量从600到7200,查询的Cassandra row从 77到740,查询耗时基本没有变化,不过Cassandra的资源消耗增加很多。
- 由2、7组可知,kairosdb client 创建的 http连接 最大数量与查询性能十分相关,R13中已调整该参数为200。
- 由6-8、14、15组可知,单Cassandra节点下,指标查询的瓶颈为 90次/分钟,且当 指标库的查询耗时 与
kairosdb查Cassandra的耗时相差不大时,可以维持稳定查询状态,否则指标库查询超时会越来越严重。
- 由8-13、17-19组可知,kairosdb的concurrentQueryThread 参数值与CPU核数一致时,性能最优;且该参数只在kairosdb 查Cassandra较慢(2S以上)时,才会产生影响。
- 由8、16组可知,指标库是否集群模式不是瓶颈。
- 由19、22和20、23两组可知,单kairosdb 8核的查询性能 与双kairosdb 4核基本相同,所以kairosdb 的查询性能与机器的CPU核数有关。
- 由19、24组可知,当前的查询瓶颈在Cassandra 处,Cassandra 集群的查询性能是单节点的10倍。
- 由24-29组可知,Cassandra集群下,查询性能瓶颈为1400次/分钟,当查询到1500次/分钟时,kairosdb出现瓶颈,等待查询线程不断增加。
- 由30、31组可知,当Cassandra写入一段时间数据后,指标查询性能下降很多。